DATAGRAM
Low-code data engineering platform
PLAY VIDEO
Would you like to develop analytical solutions based on Big Data quickly?
Use a convenient and intuitive visual development tool
Do you find there are insufficient Big Data specialists?
Take advantage of your developers’ experience in ETL and SQL for visual development of data transformation processes
Would you like to simplify support of complex solutions based on Big Data?
Introduce modifications in a quick and easy way with visual representation of data streams and their transformation processes



Visual design of Data Pipelines and automatic code generation in Scala
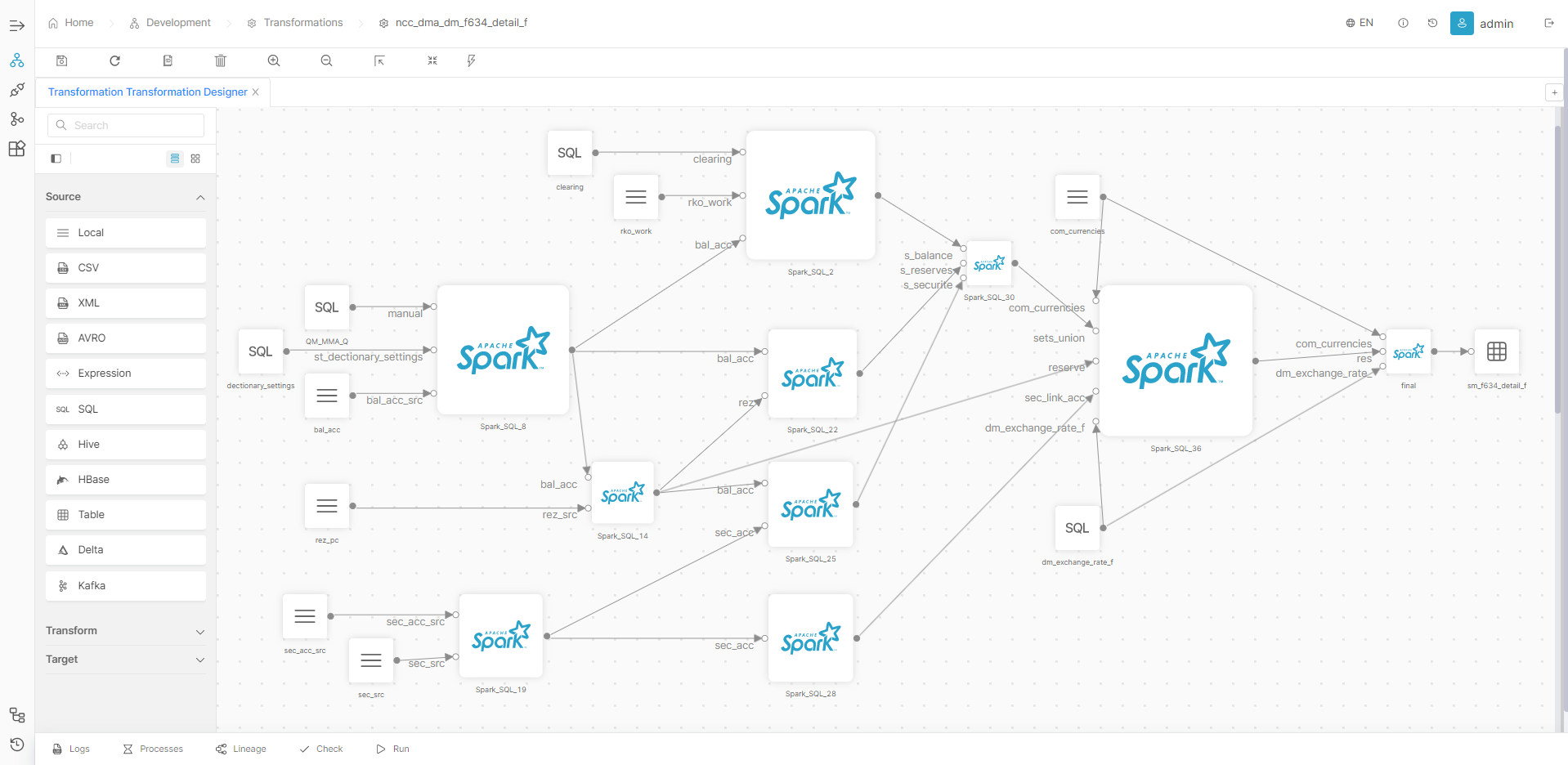
Use the full power of Apache Spark libraries for batch and streaming data processing without the need to write code in Scala manually. Scala code will be generated automatically using the Model Driven Architecture approach for special models.
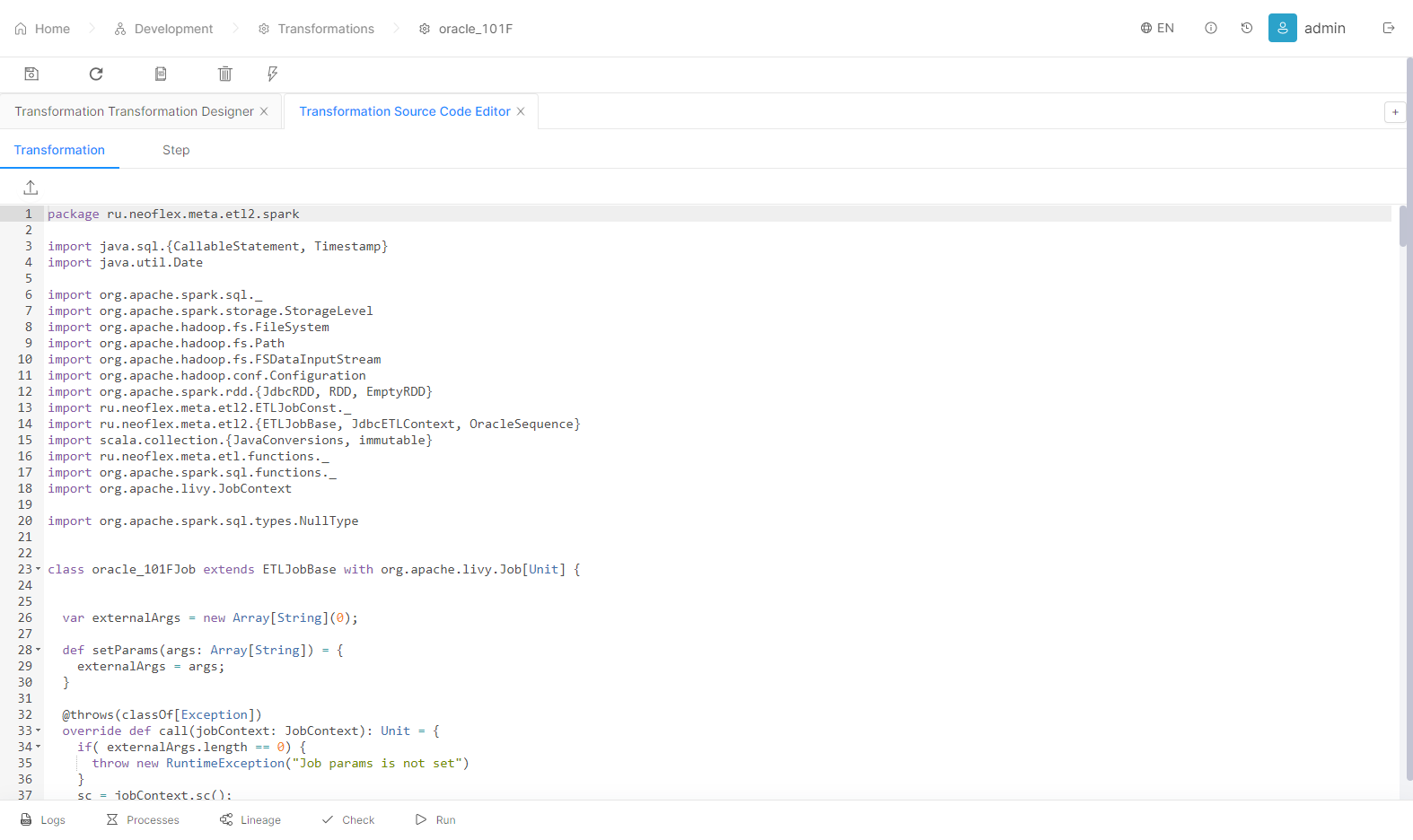

Datagram offers handy debugging and optimization tools:
View the contents and the structure of sources and listeners;
Track origins of data flow objects down to individual fields (lineage);
Perform partial transformation and review intermediary results;
Perform individual transformation steps and branches;
View generated application code;
Validate transformation automatically;
Spark Catalyst Optimizer support.
Data loading from any source in two clicks
Load data based on source metadata as is, without the need to scale down to the source-to-target mapping development. Export source metadata into Apache Atlas to build Data Governance infrastructure and manage data at the organization's level.

Streaming Processing
Design stream data transformation processes and obtain computation results within a few milliseconds after data have appeared.
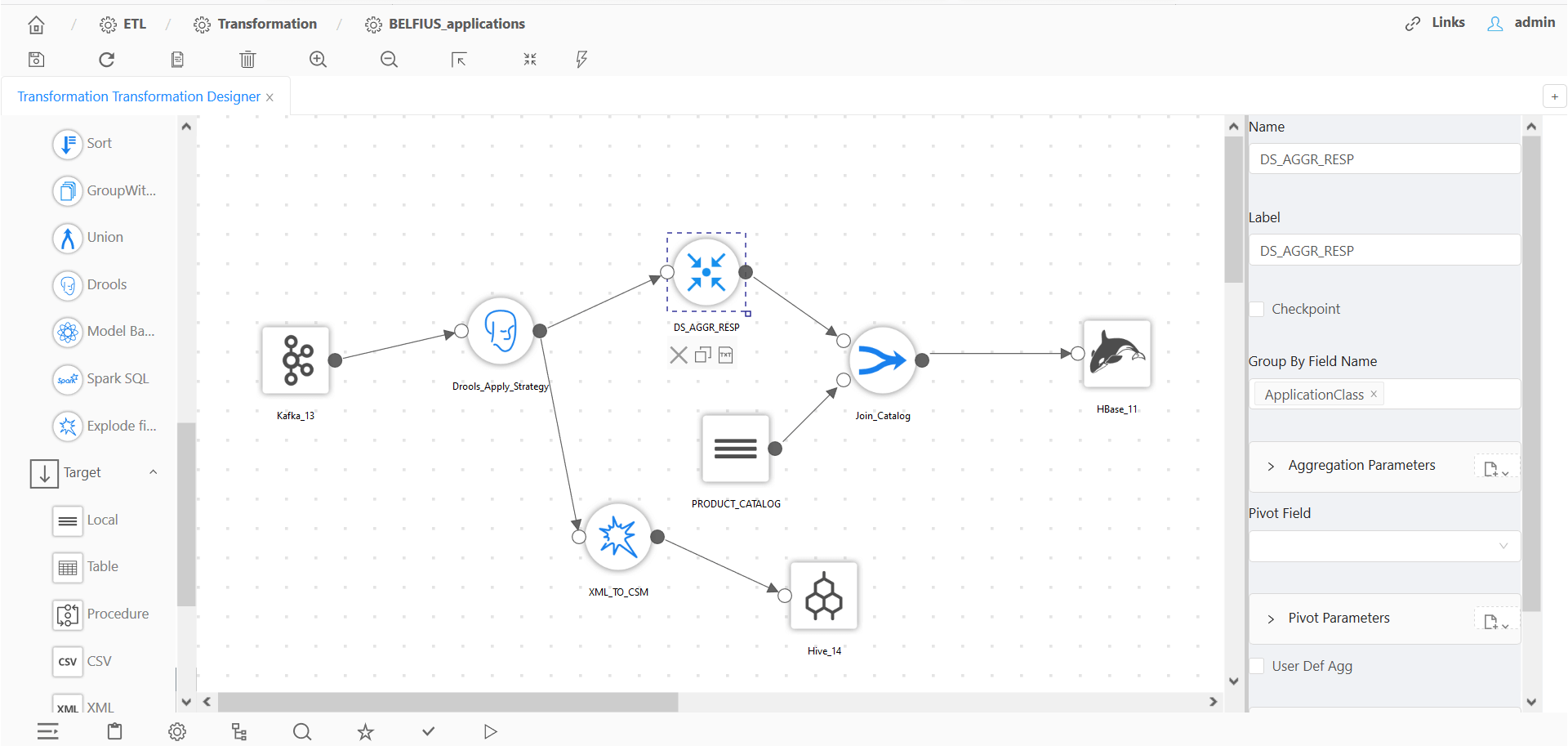
Use Kafka and Spark Streaming to process data in streaming mode. Create and use business rules for event flows in real time through native integration with BRMS.


Data Pipeline with logic
of any complexity
Integrate Artificial Intelligence/Machine Learning algorithms and business rules into data processing flows.
The broadest range of data processing tools - out of the box:
Machine-learning-based analysis with the use of Spark MLlib (decision trees, SVM, logistic regression, etc.);
Jboss Rules (Drools);
A broad range of relational algebra operations: join, sort, aggregation, union, selection, projections, pivot, explode arrays, sequence generation;
Spark SQL.

Support of DevOps and CI/СD Pipeline
Repository-based change capture
Integration with version control systems
Module assembly and installation
UNIT-test support
Launch of developed applications
Application launch does not depend on programming environment


Use the most common Hadoop versions as a run-time
DATAGRAM supports all popular Hadoop versions as a run-time. Generated spark jobs and workflows run independently from DATAGRAM during testing and production using Hadoop in-build abilities only. You can manage and monitor your data processing pipelines via advances datagram tools.
Already used in their work
